
Omnindex Journal 11/mar - Building Omnindex Extension

This is a journal I write while I build Omnindex, a search app, and post here, without much editing, just writing what comes to mind
We already have the indexer, the search engine, the twitter crawler, a logo and homepage, so, I think it's time to start building Omnindex Browser Extension. The idea of this extension is to sync your bookmarks, so we can crawl and index them for you to search later.
I did not necessarily wanted for the user to have to install any extensions, the more seamless the better, so I though of hooking on the Google or Mozilla account users use to sync their bookmarks but… no luck. Google has it totally closed, not possible to read your bookmarks, while Mozilla has a way, but it's super beta, no experimentation other than some reverse engineering some devs attempted, and Mozilla only allows usage of it in production to a few companies, provided very good reasoning for it, so… fuhgeddaboudit.
I guess it's for the best, because making a universal extension means it works with any browser no matter the company account behind it, and even for users that don't want to sync their bookmarks, a win for privacy. So, let's build an extension
Let me tell you, the best way to build an extension is to follow Mozilla WebExtensions guide, don't follow chrome guides because you will end up building things that only work for blink engine, follow WebExtensions instead, and you will build a cross-compatible extension.
I've built many web extensions and published on the stores in recent years, including the precursor of Omnindex, called Cataloger (chrome store, firefox store), so at least starting won't be a hard task, actually I will plainly copy-paste Cataloger and just clear the javascript files.
On the extension, my manifest.json looks like this:
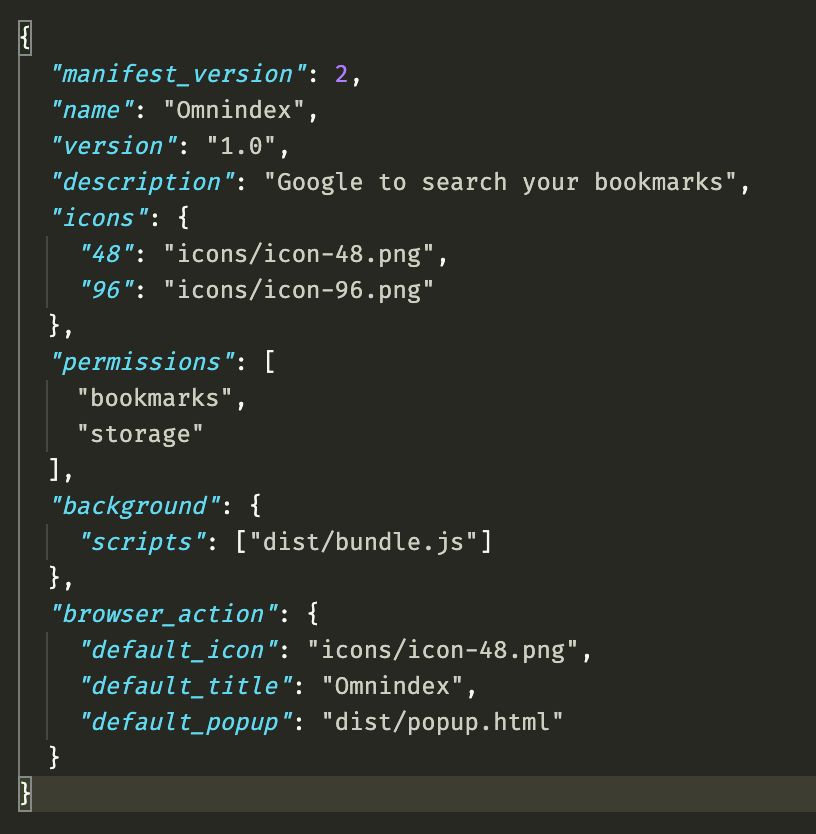
I have permission to access the bookmarks and local storage, I have a script running on the background to do the syncing, and a popup where the user will be able to see the syncing progress, kinda like you can by clicking the dropbox icon o the menu bar. I'm using webpack to bundle the js, you can notice by the "dist/bundle.js", but, since webpack generates only a single bundle (or at least I'm going with it that way), I have to use the same file on my popup.html too:
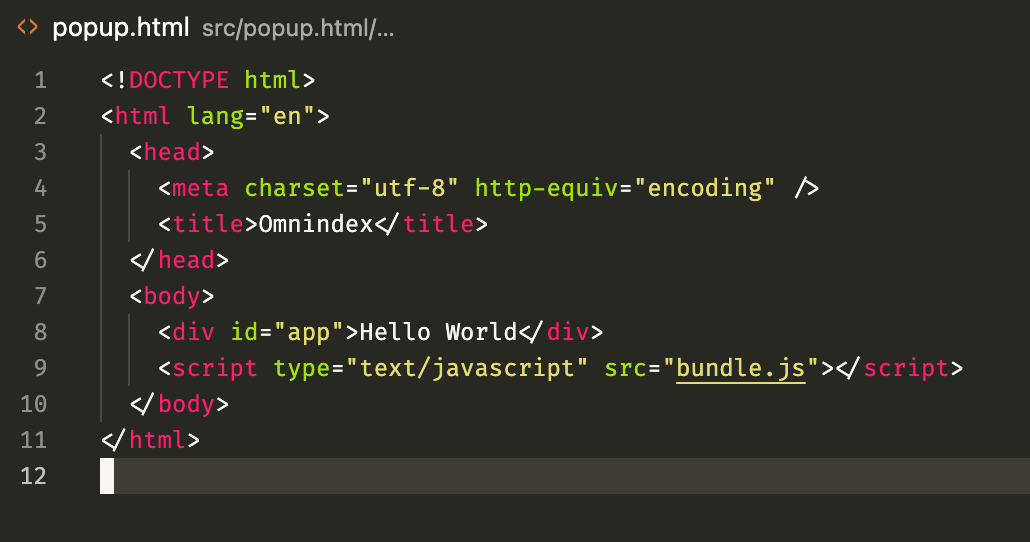
But I need different things to happen at those right? So I use this one simple trick many of you know as “the if condition”:
The popup menu works, and it looks awesome!
In the html I have "hello world", "hola mundo" actually comes from React, so I know everything is working fully.
So, the main thing for this extension should do it to sync bookmarks, it's a simple architecture, like this:
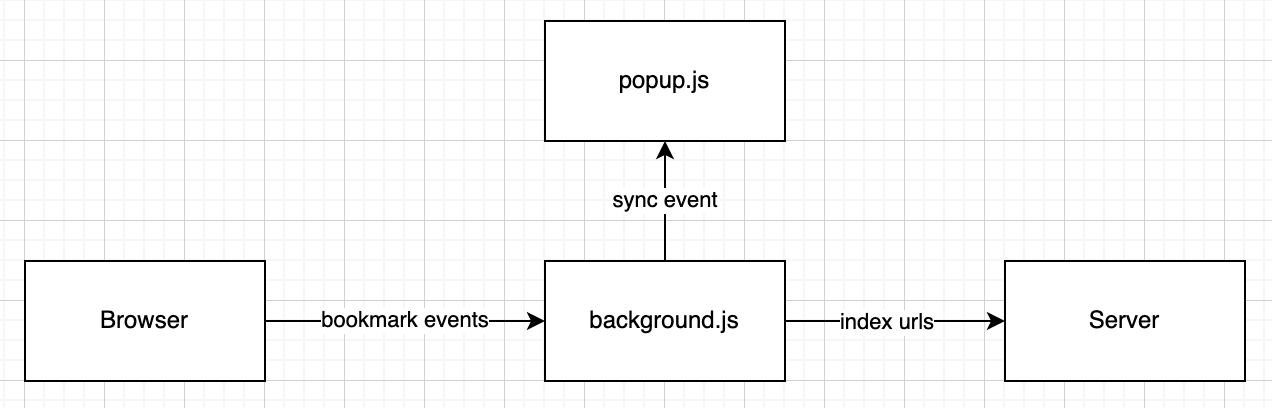
The background script listen to browser events, whenever a bookmark is added or removed (with a full sync on start), the background script then sends the links and titles of those bookmarks to Omnindex server, where we will crawl and index it.
Because the script is on the background, it can't directly affect the popup that is rendered, it has then to communicate through events, whenever a sync state changes, we can emit an event which the frontend will listen, and update the UI, since the popup won't be open all the time, I think I will probably need to send an initial event asking for the first current state, which is maintained only by the background script.
This is simple enough, the complicated part I want to get right is the actual sync, I reeeally want to make sure we have sent the bookmarks to the server, meaning that if it fails, I want to try again, with exponential backoff, until I get it right. Also, I don't want to send it all at once, for people with thousands of bookmarks, I want to send it in chunks, to not overwhelm the connection, for the server I'm not worried about because we already have a queue mechanism over there. Additionally, I want to later maybe be able to index more stuff, not only bookmarks urls, but maybe the extension could allow for example for the used to select a piece of the text on the page, saving it to be able to search later. The best tool I know fitting requirements like that would be kafka, but how to have a kafka-like stream in javascript?
Notwithstanding, I also want to sync deletes, this is a bit tricky because it's not just about listening to bookmark delete events, it could be the case that the user deletes a bunch of bookmarks on their mobile phone, and then when they fire up the browser on the computer, it's already gone, no events. So, my plan is to use localstorage to know what I already synced, and then use it as a diff when syncing, whatever is saved but don't exist in the browser anymore, means I want to delete it, the browser is my source of truth.
Okay so here is my code for that:
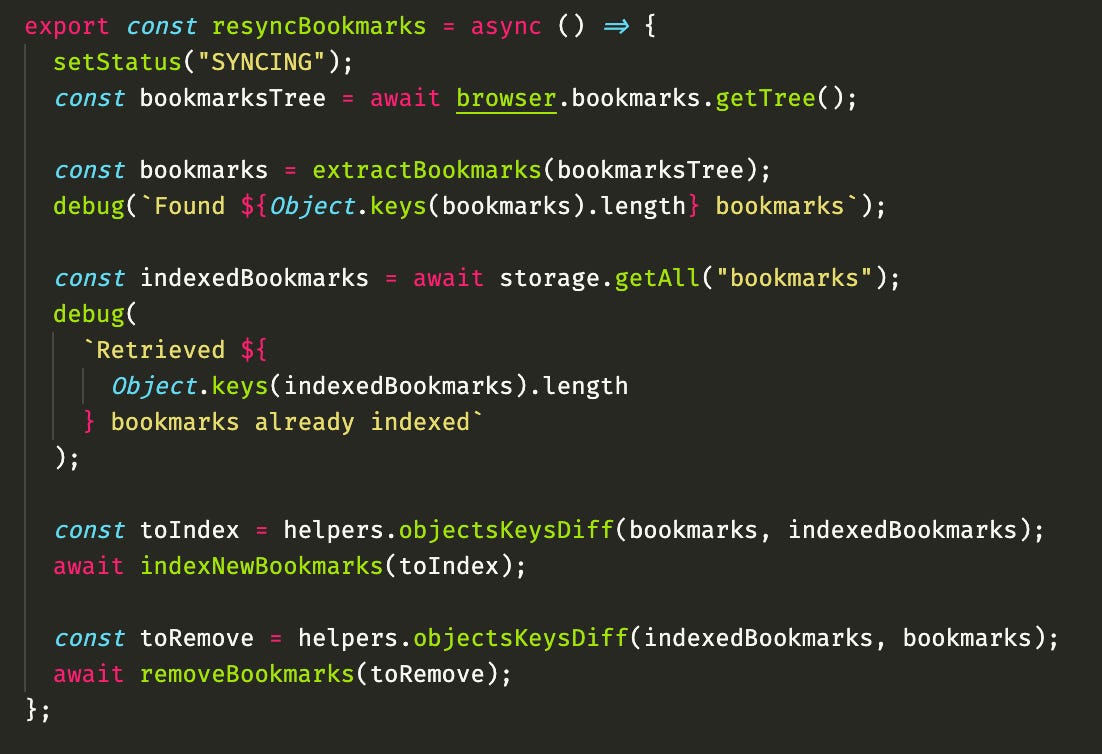
I first get ALL the bookmarks, using this WebExtension api browser.bookmarks.getTree. Because bookmarks are organized in folders, it's well, a tree. So I created a helper function extractBookmarks to flatten it to a list. I then get all the bookmarks I have saved from my storage (it's a simple key-value storage) and then I do two diffs using another helper function objectKeysDiff, whatever is in bookmarks but not index I index as new to the server, and whatever is indexed but not on the browser bookmarks, I remove from the server.
This works pretty well, and it's resilient to browser wipe-outs, meaning if the user reinstall the extension, deletes all local data or something like that, we will just reindex everything to the server, but the server can deduplicate, so no problem.
I then actually don't immediately go to the server, I actually put in a "global" variable the bookmarks I'm about to save, and call a function sync, to do the sync
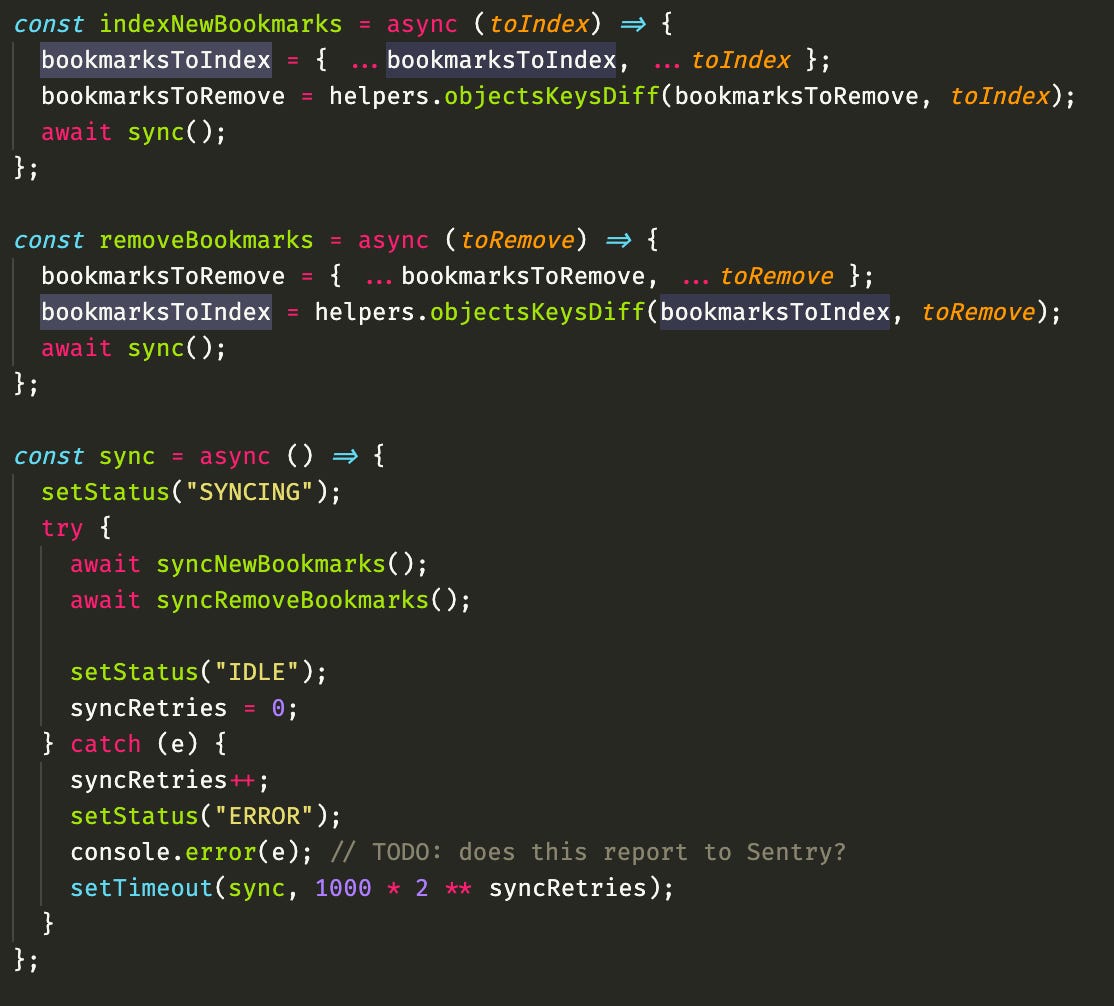
The idea is that if any error happens, I can just set a timeout to call sync again, with an exponential backoff, if some error happens, it will keep trying until it works, with time spread getting longer and longer, at the same time, other processes can run in parallel, and keep adding bookmarks to this "queue", waiting for a sync to work.
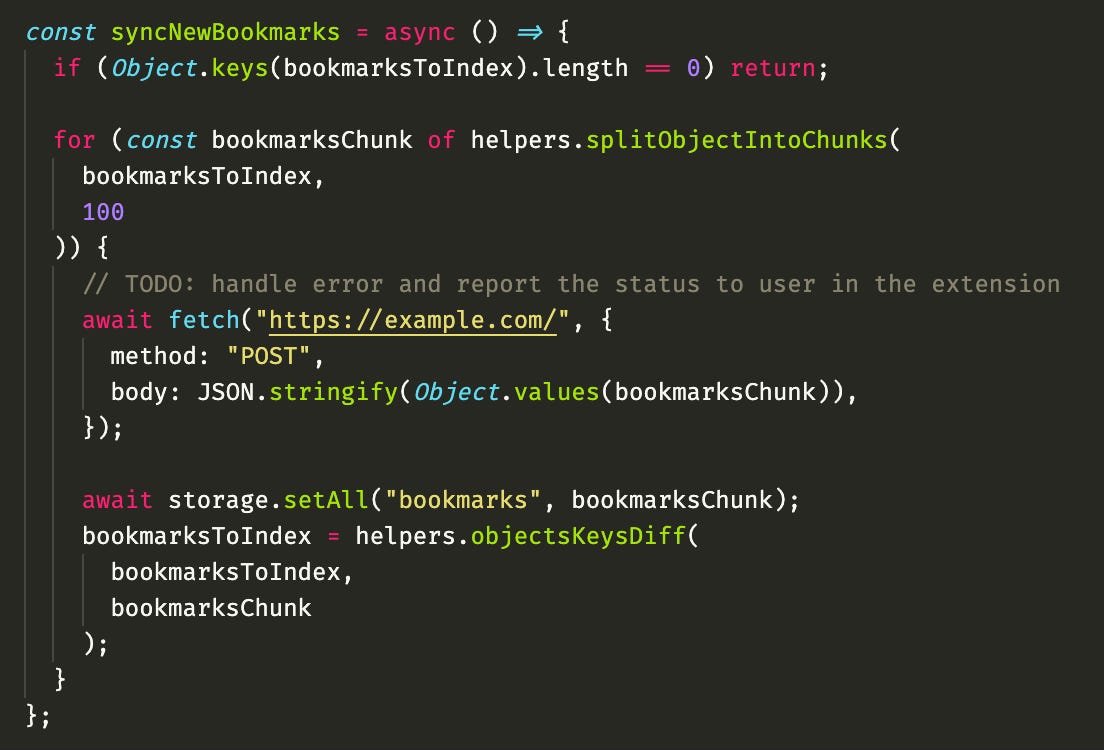
Then, on the actual function that talks to the server, I split the bookmarksToIndex "queue" into chunks of 100 items each, so I don't send a huge payload, and I remove from the "queue" after they are successful, also saving on the local storage for the next full sync
I think that was all, it's a lot of pure javascript but good enough for today, it's all tested by the way, but I do think we can leverage some fancier technology to make this more fun. Keep up for the next posts!