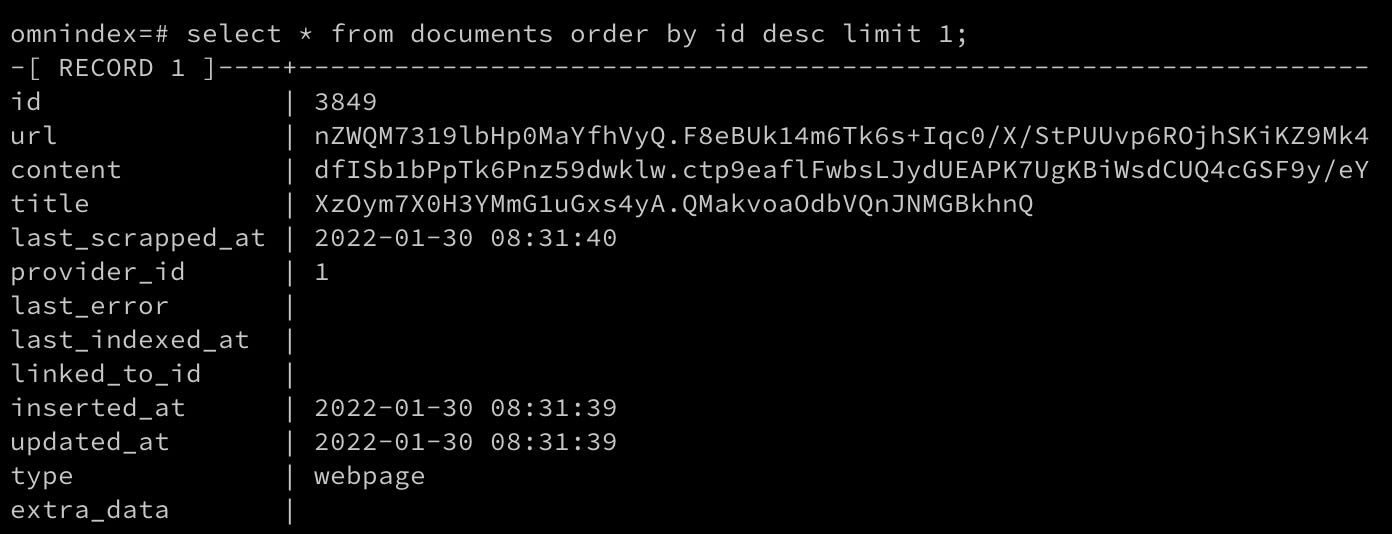
Omnindex Journal 28/jan - Encrypting all columns

This is a journal I write while I build Omnindex, a search app, and post here, without much editing, just writing what comes to mind
Okay following from the last post, let's revert Account to use a single encrypt key:
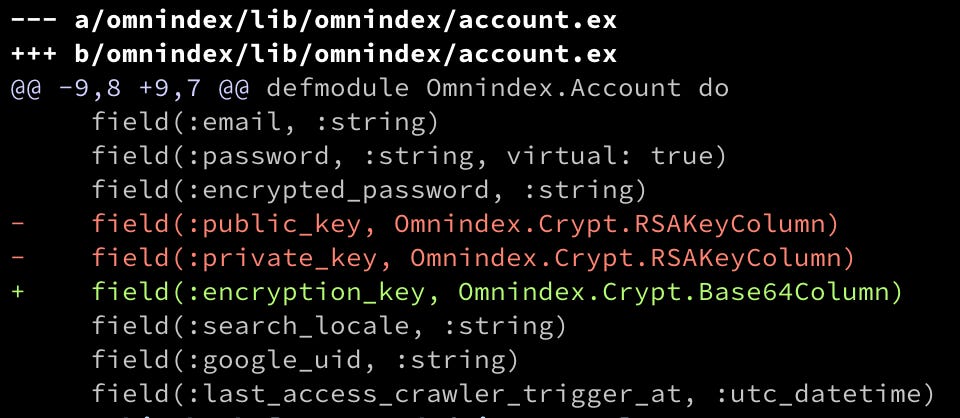
I've also changed everywhere else on the code to deal only with a single key. Cool, my content column is being encrypted on the database!

Now I also need to encrypt the other columns url, title, and extra_data, this last one is a json so it will be more tricky. So, before I had used a varchar column for url and title with rather low limit, and json type for extra_data. I don't think I'll be able to use those anymore, as with encryption fields will take more space now, and an encrypted json will not be a valid json. Reading more about it online it seems there is no much difference between varchar and text for postgres, so let's change everything to just text:

Now everything is unlimited! Hooray! I will keep the string limit on ecto side though, don't want to blow away my hard drive. I also changed my changeset function to take encryption_key as an argument, so then I can use it to encrypt all the fields that need to be encrypted:
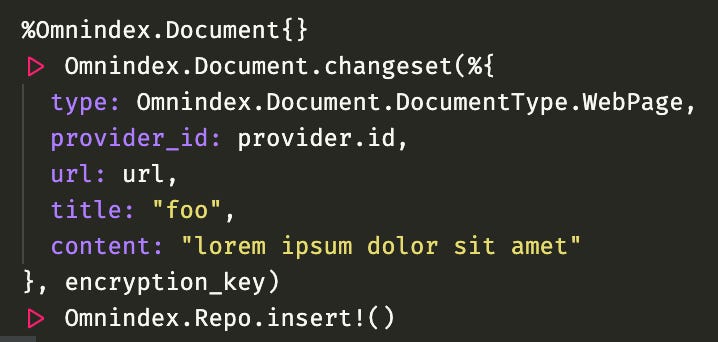
Remembering that I added the custom ecto type EncryptedStringColumn at the schema level so I cannot possibly forget to encrypt it before saving to the database otherwise an error explodes:
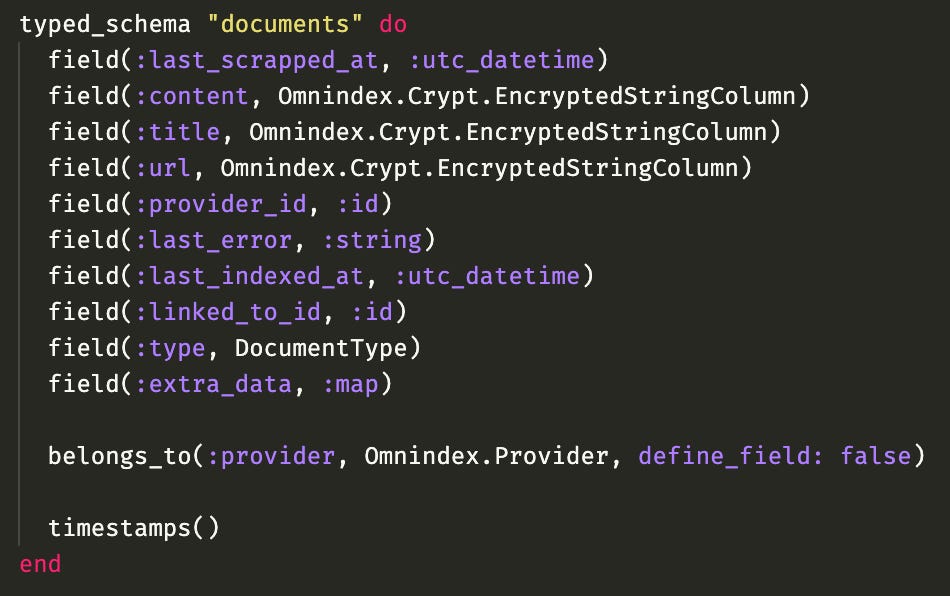
EncryptedStringColumn expects a tuple of {encription_key, str} for each field, my changeset converts each field received into this tuple, and let EncryptedStringColumn do its magic.
Last but not least, I've created an EncryptedJsonColumn for the :extra_data field, which both encodes json and encrypts it before saving to the database, and implement a function I can use to decrypt plus decode the json after retrieval:

This should be enough to make the tests pass and… oops, we have a failing test for an unexpected reason:
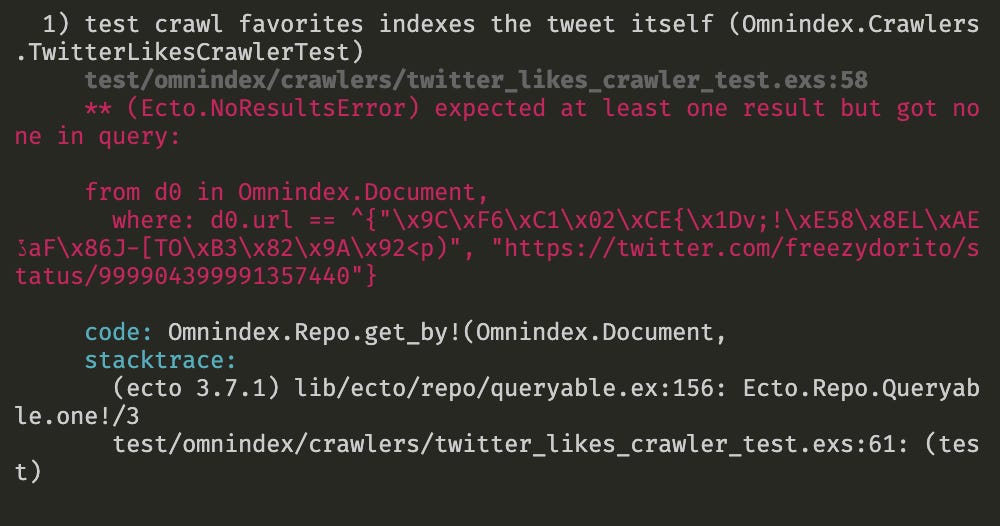
This is the test:

Basically in the setup of this test I process a tweet, and here I query the table looking for this url that was indexed. I obviously cannot search the plaintext url on the database anymore because now it's encrypted, so I pass the encryption key in the tuple. The problem is, we still can't find this record, because each time I encrypt a different random IV is generated, leading to a different encryption result, in other words, the result of my string encryption is not predictable!
Damn, this is bad, should I use a fixed IV for the url encryption perhaps? But that would weaken my encryption wouldn't it? According to wikipedia, IVs are used to achieve semantic security. Whatever that is, it sounds like an important thing, and I think that even if I remove this guarantee from url column and not from the others, if it helps an attacker to discover the real key I would end up compromising the encryption of other columns anyway.
So now I must think about my access patterns: do I really need to query by the url? Let's see, right now it doesn't seem that I do query by the url anywhere in the app, except on the tests, so I could just change the tests. But also, I'm using url as an unique index, to deduplicate, so for example if the web scrapping of a url fails, I save an error state document on the database and schedule another job for the same url, updating the document with the same url with the successful result (or another error) at the end. Additionally, I don't want to search and show results on the same url twice, in case you both bookmarked it and liked on twitter for example.
But I'm thinking all that is circumventable (is that a word?), maybe I don't need to retry the job based on the url, I could create the document beforehand and only then scrape it, using just the ID to retry. Maybe indexing the same url twice is also okay, since I already deduplicate the search results at the end anyway before displaying it to the user, and one tiny duplication basically doesn't impact performance, maybe its a good tradeoff for security.
Okay I think I will do that! I will drop the unique key constraint on url (because it's useless), I will stop querying on it entirely on the tests, and I will change the WebCrawler to be id-based rather than url-based
Okay, took me a while but here we go! Everything is encrypted now, url, content, title and extra data, I will not encrypt the other metadata fields because I will need them for querying, grouping, etc, but no personal information will be leaked